참고 자료
- 이병록님이 번역하신 HTTP 1.1 Message Syntax and Routing 번역본
https://roka88.dev/106 - MDN Web Docs
https://developer.mozilla.org/ko/docs/Web/HTTP
이외 자료는 내용 중 링크 추가
틀린 내용, 부족한 내용 꼭 지적 부탁드립니다!
3. Message Format
모든 HTTP/1.1 메시지는 인터넷 메시지 형식과 유사한 형식의 일련의 octest 시퀀스 뒤에 start-line으로 구성한다. 0 또는 여러 헤더필드 (집합적으로 “헤더” 또는 “헤더 부문”이라고 함), 헤더 부문이 끝을 나타내는 빈줄 및 선택적 메시지 본문으로 구성된다.
HTTP-message = start-line
*(header-field CRLF)
CRLF
[ message-body ]
PUT /create_page HTTP/1.1 (start-line)
Host: localhost:8000 (header-field)
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Content-Type: text/html
Content-Length: 345
(CRLF)
Body line 1 (message-body)
Body line 2
...
HTTP 메시지를 분석하는 일반적인 절차는 start-line을 읽고, 각 헤더 필드를 빈 행까지 필드 이름으로 해시 테이블로 읽은 다음 분석된 데이터를 사용하여 메시지 본문이 필요한지 여부를 확인하는 것이다. 메시지 본문이 표시된 경우, 메시지 본문 길이와 동일한 octet의 양을 읽거나 커넥션을 닫을 때까지 스트림으로 읽는다.
수신자는 반드시 HTTP 메시지를 US-ASCII의 상위 집합인 인코딩에서 octet로 굿문 분석해야 한다. 특정 인코딩에 관계 없이 HTTP 메시지를 유니코드 문자의 스트림으로 구문 분석하면 octet LF(%x0A)를 포함하는 유효하지 않은 다중 바이트 문자 시퀀스를 처리하는 문자열 처리 라이브러리의 다양한 방식 때문에 보안 취약성이 발생한다. 문자열 기반 분석기는 메시지 분석이 개별 필드를 분석 후 헤더 field-value와 같이 메시지에서 요소를 추출한 후에만 프로토콜 요소 내에서 안전하게 사용할 수 있다.
옥텟이란 말이 계속 나오는데 옥텟(octet)이란 컴퓨팅에서 8개의 비트가 한곳에 모인것을 말하고 바이트와 같은 의미이다.
HTTP 메시지는 스트림으로 구문 분석하여 증분 처리하거나 다운 스트림으로 전송할 수 있습니다. 그러나 일부 구현에서는 네트워크 효율성, 보안 검사 또는 페이 로드 변환을 위해 메시지 전달을 버퍼링 하거나 지연시키기 때문에 수신자는 부분 메시지의 증분 전달에 의존할 수 없다.
Incremental processing이라는 말이 나오는데 간단히 찾아본 결과 Incremental processing는 전체 데이터 집합을 기존 데이터가 이미 처리 된 경우 다시 처리하는 대신 새로 추가 된 데이터만 처리하는 방법이다. 이미 처리 된 데이터를 재 처리하는 오버 헤드를 제거하여 효율성을 향상시킨 처리 기술이다.
발신자는 start-line과 첫 번째 헤더 필드 사이에 공백을 보내면 안 된다. start-line과 첫 번째 헤더 필드 사이의 공백을 수신하는 수신자는 메시지를 유효하지 않은 것으로 거부하거나 메시지를 더 이상 처리하지 않고 각 공백이 지정된 줄을 소비해야 한다. (i.e., 공백이 오는 모든 후속 줄과 함께, 올바르게 형성된 헤더필드가 수신되거나 헤더 부문이 끝날 때까지, 전체 라인을 무시한다)
요청에 이러한 공백이 있으면 서버가 해당 필드를 무시하도록 속이거나 새 요청으로 처리하려고 시도한 것일 수 있으며, 요청 체인의 다른 구현에서 동일한 메시지를 다르게 해석할 경우 보안 취약성이 발생할 수 있다. 마찬가지로, 응답에 이러한 공백이 있으면 일부 클라이언트가 무시하거나 다른 사용자가 구문 분석을 중지할 수 있다.
3.1. Start Line
HTTP 메시지는 클라이언트에서 서버로 요청하거나 서버에서 클라이언트로 응답하는 것일 수 있다. 동기적으로, 두 유형의 메시지는 start-line(요청의 경우) 또는 status-line(응답의 경우)과 메시지 본문의 길이를 결정하기 위한 알고리즘에서만 다르다.
이론적으로 클라이언트는 요청을 수신할 수 있고 서버는 응답을 수신할 수 있으며, 이를 서로 다른 start-line 형식으로 구분할 수 있지만, 실제로 서버가 요청만 예상하도록 구현된다. (응답은 알 수 없거나 잘못된 요청 메서드로 해석됨). 클라이언트는 응답만을 예상하도록 구현 된다.
start-line = request-line / status-line
3.1.1. Request Line
request-line은 method 토큰을 시작으로 공백(SP), request-target, 공백, 프로토콜 버전, 그리고 CRLF를 끝으로 한다.
request-line = method SP request-target SP HTTP-version CRLF
method 토큰(GET, POST, HEAD 등…)은 대상 리소스를 실행하기 위한 요청 메서드를 표시한다. 요청 메서드는 대 소문자를 구분한다.
method = token
request-target은 요청을 적용할 대상 리소스를 식별한다.
세 구성 요소에는 공백이 허용되지 않기 때문에 일반적으로 수신자는 공백을 분할하여 request-line을 구성 요소 부분으로 분할한다. 불행하게도 일부 사용자 에이전트는 하이퍼 텍스트 참조에서 발견된 공백을 제대로 인코딩하거나 제외하지 못하여 허용되지 않는 문자가 request-target으로 전송된다.
유효하지 않은 request-line의 수신자는 400(Bad Request) 오류 또는 301(Moved Permanently) 리다이렉트로 응답해야 하며, request-target은 적절히 인코딩되어야 한다. 유효하지 않은 request-line은 요청 체인을 따라 보안 필터를 우회하도록 의도적으로 조작될 수 있으므로 수신자는 리다이렉트 없이 요청을 자동 수정하고 처리해서는 안 된다.
HTTP는 request-line의 길이에 대해 미리 정의된 제한을 두지 않는다. 구현한 것보다 더 긴 메서드를 수신한 서버는 501(Not Implemented) 상태 코드로 응답해야 한다. request-target을 구문 분석하려는 URI보다 긴 414(URI Too Long) 상태 코드로 응답해야 한다.
실제로 request-line의 길이에 대한 다양하고 특별한 목적의 제한 사항이 발견된다. 모든 HTTP 발신자와 수신자는, 최소 8000 octet 길이의 request-line을, 지원하는 것을 권장한다.
3.1.2. Status Line
응답 메시지의 첫 번째 줄은 status-line이며, 프로토콜 버전, 공백(SP), status-code, 공백, status-code를 설명하는 빈 텍스트 구문, 그리고 끝으로 CRLF이다.
status-line = HTTP-version SP status-code SP reason-phrase CRLF
status-code 요소는 서버가 클라이언트의 해당 요청을 이해하고 충족하려고 시도한 결과를 설명하는 세 자리의 정수 코드이다. 응답 메시지의 나머지 부분은 해당 상태 코드에 대해 정의된 의미론을 고려하여 해석된다.
status-code = 3DIGIT
reason-phrase 요소는 숫자 상태 코드와 관련된 텍스트 설명을 제공하는 유일한 목적으로 존재하며, 대부분 대화형 텍스트 클라이언트에서 더 자주 사용되었던 이전의 인터넷 애플리케이션 프로토콜에 대한 경의를 배제한다. 클라이언트는 reason-phase 내용을 무시해야 한다.
reason-phrase = *(HTAB/SP/VCHAR/obs-test)
reason-phrase 는 만약 상태코드가 100이라면 Continue, 200이라면 OK와 같이 상태 코드를 간략하게 설명해주는 문자열이다.
3.2. Header Fields
각 헤더 필드는 대소문자를 구분하지 않는 필드 이름 뒤에 콜론(“:”), 선택적 앞의 공백(OWS), 필드값, 선택적 뒤의 공백(OWS)으로 구성된다.
header-field = field-name ":" OWS field-value OWS
field-name = token
field-value = *(field-content / obs-fold)
field-content = field-vchar [1*(SP/HTAB) field-vchar]
field-vchar = VCHAR / obs-test
obs-fold = CRLF 1*(SP / HTAB)
;obsolete line folding
field-name 토큰은 해당 field-value를 헤더 필드에서 정의한 의미론을 갖는 것으로 레이블을 지정한다. 예를 들어 Date 헤더 필드는 메시지의 시작 타임 스탬프를 포함하는 필드로 정의 된다.
3.2.1. Field Extensibility
헤더 필드는 완전히 확장 가능하다. 새 필드 이름의 도입, 각각 새로운 의미론을 정의하는데 제한이 없다. 또한 지정된 메시지에 사용되는 헤더 필드의 개수에도 제한이 없다. 기존 필드는 이 명세의 각 부분과 이 문서 모음 외 다른 많은 명세에 정의되어 있다.
새로운 헤더 필드는 수신자가 이해할 때 이전에 정의된 헤더 필드의 해석을 재정의하거나 향상시키거나, 요청 평가에 대한 전제 조건을 정의하거나, 응답의 의미를 구체화하도록 정의할 수 있다.
field-name이 Connection 헤더 필드에 나열되어 있지 않거나 프록시가 이러한 필드를 차단하거나 변환하도록 특별히 구성되어 있지 않는 경우, 프록시는 인식하지 못하는 헤더 필드를 전달해야 한다. 다른 수신자는 인식할 수 없는 헤더 필드를 무시해야 한다. 이러한 요구 사항을 통해 배치된 중개자의 사전 업데이트를 요구하지 않고도 HTTP의 기능을 강화할 수 있다.
3.2.2. Field Order
다른 필드 이름과 헤더 필드가 수신하는 순서는 중요하지 않다. 그러나 요청 시 Host, 응답 시 Date 등 제어 데이터가 포함된 헤더필드를 먼저 보내 구현 시 메시지를 처리하지 않을 시기를 결정하는 것이 좋다. 서버는 헤더 필드에는 조건, 인증 자격 증명 또는 요청 처리에 영향을 미칠 수 있는 의도적으로 잘못된 중복 헤더 필드가 포함될 수 있으므로 ‘’
전체 요청 헤더 부문을 받을 때 까지 대상 리소스에 요청을 적용하면 안 된다. 발신자는 헤더 필드의 전체 필드 값이 쉼표로 구분된 목록으로 정의되어 있거나 헤더필드가 잘 알려진 예외가 아닌 한, 메시지에 동일한 필드 이름을 가진 헤더 필드를 여러개 생성해서는 안 된다.
수신자는 각 후속 필드 값을 쉼표로 구분하여 결합된 필드 값에 순서대로 추가하여 메시지의 의미론을 변경하지 않고 동일한 필드 이름을 가진 여러 헤더 필드를 하나의 “field-name : field-value” 쌍으로 결합할 수 있다. 따라서 동일한 필드 이름의 헤더 필드를 수신하는 순서는 결합된 필드 값을 해석하는 데 중요하다. 메시지를 전달할 때 프록시는 이러한 필드 값의 순서를 변경해서는 안 된다.
값을 쉼표로 구분한다는건 Accept-Encoding: gzip, deflate, br과 같은 경우를 나타낸다
참고 : 실제로 “Set-Cookie” 헤더 필드는 응답 메시지에 여러번 나타나며 목록 구문을 사용하지 않아 동일한 이름의 여러 헤더 필드에서 위의 요구사항을 위반한다. 필드값을 하나의 필드 값으로 결합할 수 없으므로, 수신자는 헤더 필드를 처리하는 동안 “Set-Cookie”를 특별한 경우로 처리해야 한다.
3.2.3. Witespace
이 명세는 OWS(선택적 공백), RWD(필수 공백) 및 BWS(잘못된 공백)의 사용을 나타내는 세가지 규칙을 사용한다.
OWS 규칙은 0 이상의 선형 공백 octets이 나타나는 곳에 사용된다. 가독성을 향상시키기 위해 선택적인 공백(OWS)을 선호하는 프로토콜 요소의 경우, 발신자는 단일 SP로서 선택적인 공백(OWS)를 생성해야 한다. 그렇지 않은 경우, 발신자는 내부 메시지 필터링 중에 유효하지 않거나 원하지 않는 프로토콜 요소를 화이트아웃 하는 데 필요한 경우를 제외하고 선택적 공백을 생성해서는 안 된다.
RWS 규칙은 필드 토큰을 불리하기 위해 하나 이상의 선형 공백 octets이 필요한 경우에 사용 된다. 발신자는 단일 SP로서 RWS를 생성해야 한다.
BWS 규칙은 오직 역사적인 이유로 선택적인 공백(OWS)을 허락하는 문법에서 사용된다. 발신자는 메시지에서 BWS를 생성해서는 안 된다. 수신자는 이러한 잘못된 공백을 구문 분석한 후 프로토콜 요소를 해석하기 전에 제거해야 한다.
OWS = *(SP / HTAB) 공백이 0개 이상
;optional whitespace
RWS = 1*(SP / HTAB) 공백이 1개 이상
;required whitespace
BWS = OWS 공백이 0개 이상
;"bad" whitespace
3.2.4. Field Parsing
메시지는 개별 헤더 필드 이름과 독립적으로 일반적인 알고리즘을 사용하여 구문 분석된다. 주어진 필드 값 내의 내용은 메시지 해석의 이후 (일반적으로 메시지 전체 헤더 부문이 처리된 후)까지 구분 분석되지 않는다. 따라서 이 규격은 각 “Field-Name : Filed-Value” 쌍은 이전 버전에서와 같다. 대신, 이 명세는 등록된 각 필드 이름에 따라 명명된 ABNF 규칙을 사용한다. 여기서 규칙은 해당 필드의 해당 필드 값에 대한 유효한 문법을 정의한다. (즉, 일반적인 필드 구문 분석기에 의해 헤더 부문에서 field-value를 추출한 후)
헤더 field-name과 콜론 사이에는 공백이 허용되지 않는다. 과거에는 이러한 공백 처리에 차이가 있어 요청 라우팅 및 응답 처리 시 보안 취약성이 발생했다. 서버는 응답 코드가 400(Bad Request)과 함께 헤더 필드 이름과 콜론 사이에 공백이 포함된 수신된 요청 메시지를 거부해야 한다. 프록시는 메시지를 다운 스트림으로 전달하기 전에 응답 메시지에서 이러한 공백을 모두 제거해야 한다.
HTTP/1.1 200 OK
Etag: 1e8d0b-b3e8-6049b0e8
Content-Type: text/html; charset=utf-8
Content-Length: 46056
Last-Modified: Thu, 11 Mar 2021 05:55:52 GMT
Cache-Control: private, max-age=0, proxy-revalidate, no-store, no-cache, must-revalidate
Server: WEBrick/1.4.2 (Ruby/2.6.3/2019-04-16)
Date: Thu, 11 Mar 2021 06:02:03 GMT
Connection: Keep-Alive
요청에 대한 응답 헤더 중 일부를 예로 들면 헤더의 필드네임에서 콜론이 오기전까지 공백이 있는 헤더는 존재하지 않는것을 볼 수 있다.
필드 값은 OWS 앞에 있거나 뒤에 있을 수 있으며, 필드 값 앞에 있는 단일 SP는 사람이 일관 되게 읽을 수 있도록 선호한다. 필드 값에는 선행 또는 후행 공백이 포함되어 있지 않다. 필드 값의 첫번째 공백이 아닌 octet 이전 또는 필드 값의 마지막 공백이 아닌 octets 이후에 발생하는 OWS는 헤더 필드에서 필드 값을 추출할 때 파서에 의해 제외되어야 한다.
이 내용 또한 위의 예제를 보면 알 수 있다.
역사적으로, HTTP 헤더 필드 값을 각 여러 줄 앞에 최소 하나 이상의 공백 또는 수평 탭(obs-fold)을 두어 여러줄로 확장할 수 있었다. 이 명세는 message/http 미디어 타입을 제외하고 이러한 라인 폴딩을 제거한다. 발신자는 메시지가 message/http 미디어 타입 내에서 패키징 되도록 의도되지 않은 한 라인 폴딩(즉, obs-fold 규칙과 일치하는 field-value 포함)을 포함하는 메시지를 생성해서는 안 된다.
message/http 컨테이너 내에 없는 요청 메시지에서 obs-fold를 수신하는 서버는 400(Bad Request)을 발송하여 메시지를 거부해야 하며, 가급적이면 사용되지 않는 라인 폴딩이 허용되지 안흔ㄴ다는 것을 설명하는 표현으로, 필드 값을 해석하거나 또는 메시지를 다운스트림으로 전달하기 전에, 수신된 각 obs-fold를 하나 이상의 SP octet으로 대체해야 한다.
message/http 컨테이너 내에 없는 응답 메시지에서 obs-fold를 수신하는 프록시 또는 게이트 웨이는 메시지를 삭제하고 502(Bad Gateway) 응답으로 대체해야 하고, 가급적이면 사용되지 않는 라인 폴딩이 허용되지 않는 다는 것을 설명하는 표현으로, 필드 값을 해석하거나 또는 메시지를 다운 스트림으로 전달하기 전에, 수신된 각 obs-fold를 하나 또는 더 많은 SP octets으로 대체해야 한다.
message/http 컨테이너 내에 없는 응답 메시지에서 obs-fold를 수신하는 사용자 에이전트는 필드 값을 해석하기 전에, 수신된 각 obs-fold를 하나 또는 더 많은 SP octets으로 대체해야 한다.
역사적으로, HTTP는 ISO-8859-1 charset의 텍스트를 포함한 필드 컨텐츠를 허용해 왔으며, 인코딩의 사용을 통해서만 다른 문자 집합을 지원해 왔다. 실제로 대부분의 HTTP 헤더 필드 값은 US-ASCII 문자 집합의 하위 집합만 사용한다. 새로 정의된 헤더 필드는 필드 값을 US-ASCII octet으로 제한해야 한다. 수신자는 필드 내용(obs-test)의 다른 octet을 불투명 데이터로 처리해야 한다.
Header: value1,
value2
Header: value1, value2
위 두 헤더는 같은 의미를 가지는데 해석하기 이전에 obs-fold(CRLF)를 공백으로 대체해야 한다(위 모양에서 아래 모양으로).
3.2.5. Field Limits
HTTP는 각 헤더 필드의 길이 또는 헤더 부문의 전체 길이에 미리 정의된 제한을 두지 않는다. 실제로 개별 헤더 필드 길이에 대한 다양한 특별한 목적의 제한사항이 발견되며, 종종 특정 필드 의미론에 따라 달라진다.
처리하려는 것보다 큰 요청 헤더 필드 또는 필드 집합을 수신하는 서버는 적절한 4xx(Client Error)상태 코드로 응답해야 한다. 이러한 헤더 필드를 무시하면 서버의 smuggling 공격 취약성이 증가한다.
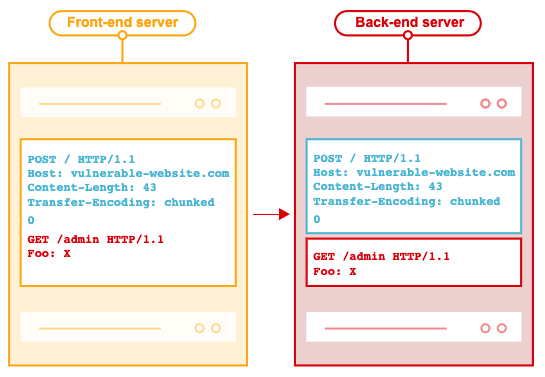
smuggling 공격에 대한 예. 헤더의 필드 벨류에 또 다른 요청문이나 악의적인 행위를 할 수 있는 내용을 포함하여 백엔드 서버에서 메시지를 수신할때 악의적인 쪽으로 메시지를 해석할 수 있다.
필드 의미론이 메시지 프레임 또는 응답 의미론을 변경하지 않고 손실된 값을 안전하게 무시할 수 있는 경우 클라이언트가 처리하고자 하는 것보다 더 큰 수신된 헤더 필드를 삭제하거나 잘라낼 수 있다.
3.2.6. Field Value Components
대부분의 HTTP 헤더 필드 값은 공백 또는 특정 구분 문자로 구분된 일반 구문 구성 요소(token, quoted-string, comment)를 사용하여 정의 된다. 구분 기호는 토큰 (DQUOTE and “(),/:;<=>?@[₩]{}”)에 허용되지 않는 US-ASCII 시각적 문자 집합에서 선택된다.
token = 1*tchar
tchar = "!" / "#" / "$" / "%" / "&" / "'" / "*"
/ "+" / "-" / "." / "^" / "_" / "`" / "|" / "~"
/ DIGIT / ALPHA
; any VCHAR, except delimiters
텍스트 문자는 double-quote로 묶여 있으면 하나의 값으로 분석된다.
quoted-string = DQUOTE *( qdtext / quoted-pair ) DQUOTE
qdtext = HTAB / SP /%x21 / %x23-5B / %x5D-7E / obs-text
obs-text = %x80-FF
코멘트는 괄호로 둘러싸인 텍스트를 둘러싼 일부 HTTP 헤더 필드에 포함될 수 있다. 주석은 필드 값 정의의 일부로 “comment”를 포함하는 필드에서만 허용된다.
comment = "(" *(ctext/quoted-pair/comment) ")"
ctext = HTAB / SP / %21-27 / %x2A-5B / %x5D-7E / obs-text
backslash octet (“₩”)는 quoted-string 메커니즘 및 주석 구조 내에서 single-octet으로 사용할 수 있다. quoted-string 값을 처리하는 수신자는 quoted-pair를 백슬래시로 octet에 의해 대체된 것 처럼 처리해야 한다.
quoted-pair = "₩" (HTAB/SP/VCHAR/obs-text)
발신자는 DQUOTE와 백슬래시 octets을 해당 문자에 이용해야 하는 경우를 제외하고 quoted-string에서 quoted-pair를 생성하면 안 된다. 발신자는 괄호 [”(“and”)”]와 backslash octets를 해당 주석에 인용해야 하는 경우를 제외하고 comment 내에 quoted-pair를 생성하면 안 된다.
3.3. Message body
HTTP 메시지의 메시지 본문(있는 경우)은 해당 요청 또는 응답의 페이로드 본문을 전달하는데 사용된다. 메시지 본문은 전송 코딩이 적용되어 있찌 않는한 페이로드 본문과 동일하다.
message-body = *OCTET
메시지에서 메시지 본문이 허용되는 시기에 대한 규칙은 요청과 응답에 따라 다르다.
요청에서 메시지 본문이 있으면 Content-Length 또는 Transfer-Encoding 헤더 필드로 표시된다. 요청 메시지 프레임은 메서드가 메시지 본문에 대한 사용을 정의하지 않더라도 메서드 의미론과 독립적이다.
응답에서 메시지 본문의 존재 여부는 응답하는 요청 메서드와 응답 상태코드에 따라 달라진다. HEAD 요청 메서드에 대한 응답은 관련 응답 헤더 필드(Transfer-Encoding, Content-Length 등)가 있는 경우 요청 메서드가 GET 되었을 때의 값만 나타내므로 메시지 본문을 포함하지 않는다. CONNECT 요청 메서드에 2xx(successful) 응답은 메시지 본문 대신 터널 모드로 전환한다. 모든 1xx(Informational), 204(No Content) 및 304(Not Modified) 응답에는 메시지 본문이 포함되지 않는다. 다른 모든 응답에는 메시지 본문이 포함되지만, 본문의 길이는 0일 수 있다.
3.3.1. Transfer-Encoding
Transfer-Encoding 헤더 필드에는 메시지 본문을 형성하기 위해 페이로드 본문에 적용된 (또는 적용될) transfer-coding 순서에 해당하는 transfer-coding 이름을 나열한다.
Transfer-Encoding = 1#transfer-coding
Transfer-Encoding은 MIME의 Content-Transfer-Encoding 필드와 유사하며, 7비트 전송 서비스를 통해 바이너리 데이터를 안전하게 전송할 수 있도록 설계 되었다. 그러나, 안전한 전송은 8bit-clean 전송 프로토콜에 대한 다른 초점을 두고 있다. HTTP의 경우, Transfer-Encoding은 주로 동적으로 생성된 페이로드를 정확하게 구분하고 전송 효율성 또는 보안에만 적용되는 페이로드 인코딩을 선택한 리소스의 특징과 구별하기 위한 것이다
Transfer-Encoding 헤더는 사용자에게 entity(엔티디 헤더, 헤더 명 앞에 Content가 붙은 헤더들이다)를 안전하게 전송하기 위해 사용하는 인코딩 형식을 지정한다. Transfer-Encoding은 hop-by-hop 헤더로, 리소스 자체가 아닌 두 노드 사이에 메시지를 적용하는 것이다. 다중-노드 연결의 각각의 세그먼트는 Transfer-Encoding의 값을 다르게 사용할 수 있다.(단일 통신이 아닌 거쳐서 통신할 경우) 만약 전체 연결에 있어 데이터를 압축하고자 한다면, end-to-end 헤더인 Content-Encoding 헤더를 대신 사용 (단인 전송 수준 연결만 의미 있으며 프록시에 의해 재 전송되거나 캐시되지 않아야한다. Connection 헤더를 사용하여 홉별 헤더만 설정할 수 있다)
페이로드 본문 크기를 미리 알 수 없을 때 메시지 프레임에 중요한 역할을 하기 때문에 수신자는 chunked transfer coding을 구문 분석할 수 있어야 한다. 발신자는 메시지 본문에 두번 이상 청크 분할된 메시지를 적용해서는 안 된다. (i.e., 이미 청크 분할된 메시지는 허용되지 않는다). 청크 분할 이외의 transfer coding이 요청 페이 로드 본문에 적용되는 경우, 발신자는 메시지가 올바르게 프레임 되었는지 확인하기 위해 최종 transfer-coding으로 청크 분할을 적용해야 한다. 청크 분할 이외의 전송 코딩이 응답 페이로드 본문에 적용되는 경우 발신자는 최종 전송 코딩으로 청크 분할을 적용하거나 커넥션을 닫아 메시지를 종료해야 한다.
Transfer-Encoding: gzip, chunked
예를 들어 위 예제는 메시지 본문을 구성하는 동안 페이로드 본문이 gzip 코딩을 사용하여 압축된 다음 chunked 코드를 사용하여 분할된 것을 나타낸다. 아래는 청크 분할 인코딩의 예제이다.
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
7\r\n
Mozilla\r\n
9\r\n
Developer\r\n
7\r\n
Network\r\n
0\r\n
\r\n
Content-Encoding과 달리 Transfer-Encoding은 메시지의 속성이며 표현이 아니다. 요청/응답 체인에 있는 모든 수신자는 Transfer-Encoding field-value에 변경사항이 있다면 수신된 전송 코딩을 디코딩하거나 추가 전송 코딩을 본문에 적용할 수 있다. 추가적인 인코딩 매개 변수에 대한 정보는 이 명세에 정의되지 않은 다른 헤더 필드로 제공되어진다.
Transfer-Encoding에 대해서 Content-Encoding과 차이가 와닿지 않아서 찾아본 결과 Transfer-Encoding은 체인 관계에서 홉 단위로 설정되며 Content-Encoding은 end-to-end 단위로 설정된다. 또한 Transfer Encoding은 청크 이외에 실제로 구현되지 않았으며, 메시지 계층을 인코딩하며(그렇기 때문에 엔티티 태그에 영향을 준다.), Content Encoding은 페이로드 계층을 인코딩한다.
HEAD 요청에 응답하거나 또는 304(Not Modified) 응답을 통해 GET 요청에 응답하거나, 메시지 본문을 포함하거나 조건 없는 GET 요청인 경우 오리진 서버가 메시지 본문에 transfer-coding을 적용 했을거라고 표시하기 위해 Transfer-Encoding이 보내질 수 있다. 그러나 응답 체인(오리진 서버 포함)에 있는 모든 수신자는 transfer-coding이 필요하지 않을 때 제거할 수 있기 때문에 이러한 표시는 필요하지 않다.
서버는 상태 코드가 1xx(Informational) 또는 204(No Content) 응답에서 Transfer-Encoding 헤더 필드를 보내면 안 된다. 서버는 CONNECT 요청에 2xx(Successful) 응답에서 Transfer-Encoding 헤더 필드를 보내면 안 된다.
HTTP/1.1에 Transfer-Encoding이 추가 되었다. 일반적으로 HTTP/1.0 지원만 알리는 구현은 전송 인코딩된 페이로드를 처리하는 방법을 이해하지 못할 것으로 가정됩니다. 클라이언트는 서버가 HTTP/1.1(이상) 요청을 처리 할 수 있을 것이라고 알지 못하는 한 Transfer-Encoding을 포함하는 요청을 보내면 안된다. 이러한 인지는 특정 사용자 구성 형태이거나 이전에 수신한 응답 버전을 기억함으로써 가능하다. 해당 요청이 HTTP/1.1(또는 그 이상)을 나타내지 않는 한 서버는 Transfer-Encoding을 포함하는 응답을 보내면 안 된다.
이해하지 못하는 transfer coding과 함께 요청 메시지를 받는 서버는 501 (Not Implemented)로 응답해야 한다.