참고 자료
- 이병록님이 번역하신 HTTP 1.1 Semantics and Content 번역본
https://roka88.dev/106 - MDN Web Docs
https://developer.mozilla.org/ko/docs/Web/HTTP
이외 자료는 내용 중 링크 추가
틀린 내용, 부족한 내용 꼭 지적 부탁드립니다!
HTTP 1.1 Reference - Semantics and Content
1. 간단한 설명
HTTP 메시지는 요청 또는 응답을 나타낸다.
서버는 클라이언트에게 요청을 받고 수신된 메시지를 해석 후 허락된 클라이언트에게 하나 이상의 응답 메시지를 반환한다. (서버가 먼저 클라이언트에게 요청할 수 는 없다. 웹소켓 제외)
클라이언트는 특정한 의도를 나타내는 요청 메시지를 서버에게 보낸후 수신된 응답을 확인하여 (상태 코드 확인) 의도대로 수행되었는지 확인 후 응답 메세지를 결과를 확인한다(Response Body의 내용을 확인).
2. Resources
HTTP의 요청 대상을 resource라고 부른다. HTTP는 리소스와 상호 작용을 할 수 있는 인터페이스(아마 HTTP가 요청과 응답하는 구조의 내용일듯)를 정의하고 리소스는 URI로 식별된다.
HTTP의 설계 목표 중 하나는 요청의 의미론에서 리소스 식별을 분리 하는것이다. 예를 들어 URI는 리소스를 처리할 행위 모두를 나타내는것이 아니라 URI는 리소스를 식별하는 역할만 하는것이고 메소드나 다른 헤더를 통해 어떠한 역할을 수행해야하는지를 식별하도록 하는것이다. 그렇기 때문에 URI는 겹칠 수 있지만 메소드가 다를 경우 다른 동작을 하게 되는 것이다.
POST http://localhost/get_user
위에 내용을 보충 해보면 조금 극단적인 예라 생각 하지만 위 요청처럼 URI에 리소스에 대한 행위를 담는것이 아니라 아래처럼 메소드나 부가적인 헤더를 이용하여 행위를 나타내는것이 HTTP 설계 목표이다. (라고 이해했다 나는…)
GET http://localhost/user
POST http://localhost/user
3. Representations
참고자료 (https://blog.npcode.com/2017/04/03/rest의-representation이란-무엇인가/)
리소스는 무엇이든 될 수 있으며 해당 행위들은 여러가지가 될 수 있다. 이러한 점에서 우리는 서버에 원하는 요청(상태)를 나타내기위한 추상화가 필요한데 그 추상화를 우리는 REST라고 부른다.
HTTP의 목적 상 Representations는 주어진 리소스의 상태(과거, 현재, 또는 원하는 상태)를 프로토콜을 통해 쉽게 전달할 수 있는 형식으로 반영하기 위한 정보이다. 표현 데이터는 데이터 스트림으로 구성된다.
Representations의 예를 들어보면 아래의 요청에 대해 아래와 같은 응답들을 볼 수 있다. 이러한 응답들을 representation이라고 한다. 첫번째는 사용자1이라는 리소스를 한글 사용자들을 위한 상태로 반환 한것이다. 두번째는 영문 사용자, 세번째는 html로, 네번째는 json의 형태로 반환 한것이다.
GET http://localhost/user
Content-Type: text/plain
Content-Language: ko
응답 : 사용자1
GET http://localhost/user
Content-Type: text/plain
Content-Language: en
응답 : user1
GET http://localhost/user
Content-Type: text/html
응답 : <html><body>사용자1</body></html>
GET http://localhost/user
Content-Type: application/json
응답 : {'name' : 'user1'}
3.1. Representation Metadata
Representation 헤더 필드는 Representation에 대한 메타 데이터를 제공한다. 메시지에 페이로드 본문이 포함된 경우 Representation header 필드에는 본문에 포함된 Representation 데이터를 해석하는 방법을 나타낸다.
3.1.1. Processing Representation Data
3.1.1.1. Media Type
HTTP는 유연한 데이터 입력과 반환을 위해 Content-Type과 Accept헤더 필드를 사용한다. 미디어 타입은 데이터 형식과 다양한 처리 모델을 정의 할 수 있다. 결론적으로 미디어 타입은 데이터가 어떤 모양으로 수신 됐으며 어떤 모양으로 반환을 해야한다는 정보를 명시해주는 것이다.
media-type = type / subtype 형태를 이룬다. 다들 알다 시피 text/html이나 application/json등 이러한 형태이다. type과 subtype는 대소문자를 구분하지 않는다. 이후 type / subtype; parameter=token과 같은 형태가 있으며 이때 parameter의 값인 token은 parameter에 따라 대소문자를 구분하거나 구분하지 않을 수 있다. 또한 = 앞과 뒤에는 공백을 허용하지 않는다. 예를 들면 text/html;charset=utf8과 같은 형태이다. 뒤에 붙는 매개 변수의 존재나 부재는 미디어 타입 레지스트리 내의 정의에 따라 미디어 타입 처리에 중요할 수 있다.
3.1.1.2. Charset
Charset는 HTTP의 문자 인코딩 방식을 표현할때 사용한다. Charset는 대소문자를 구분하지 않는다.
3.1.1.3. Canonicalization and Text Defaults (정규화 및 텍스트 기본 값)
text 타입의 미디어 하위 타입이 텍스트 줄바꿈을 할땐 CRLF를 사용하여야 한다. HTTP는 이러한 줄 바꿈이 전체 표현에 일관 될 때, 줄 바꿈을 나태는것을 CR 또는 LF만으로 텍스트를 전송할 수 있다. 줄바꿈과 관련됨 내용은 ‘text’ 미디어 타입이 할당 된 Representation 내 텍스트에만 적용 된다.
3.1.1.4. Multipart Types ( 참고 내용 : https://qssdev.tistory.com/47)
단일 메시지 본문 내에서 하나 이상의 표현을 캡슐화한 여려 “multipart” 타입을 제공한다. 대부분 데이터 전송 ‘multipart/form-data’ 타입을 사용하는 경우가 많다. 멀티파트 타입은 미디어 타입 값의 일부로 경계 매개변수를 포함한다. 경계 매개 변수를 예를 들어 보면 아래와 같다.
<form action = "http://localhost/images"
enctype = "multipart/form-data"
method = "post">
<input type="text" name = "imageName"><br>
<input type="file" name = "image"><br>
<input type="submit" name = "upload"><br>
</form>
위 처럼 폼을 만들어주고 Request 구문을 생성한것이 아래와 같다. 바운더리 변수가 만들어지고 form data의 타입마다 경계를 주어 구문을 분석한다. 메시지 본문은 그 자체로 프로토콜 요소이며 발신자는 본문 부분 사이의 줄 바꿈을 나타내기위해 CRLF만 생성해야한다.
POST /images HTTP/1.1
Host: localhost
Content-Length: 228
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="imageName"
image
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="file"
123412341234
----WebKitFormBoundary7MA4YWxkTrZu0gW
3.1.1.5. Content-Type
Content-Type 헤더 필드는 메시지에 포함된 페이로드(메시지 본문(body)이라고 생각)의 미디어 타입을 나타낸다. 미디어 타입은 representations을 디코딩과 인코딩 하는 정보를 제공한다. representation을 발신자가 알 수 없는 경우가 아니라면 Content-Type 헤더 필드를 생성해야 한다. 만약 없는 경우 수신자는 application/optet- stream라는 미디어 타입을 가정하거나 데이터를 검토하여 타입을 결정할 수 있다. 리소스 소유자가 올바른 Content-Type을 제공하도록 구성하지 않으면 클라이언트가 메시지의 본문을 콘텐츠 검사하고 지정된 타입을 재정의 한다. 잘못된 타입으로 정의할 수 있으며 보안 위험(예를 들면 privilege escalation,(https://ko.wikipedia.org/wiki/권한_확대) 권한 확대라는 보안 위험인데… 잘 모르겠다.)이 생길 수 있다. 구현자는 content sniffing을 방지할 수 있는 수단을 제공해야한다. (https://en.wikipedia.org/wiki/Content_sniffing)
3.1.2. Encoding for Compression or Integrity (압축 또는 무결성을 위한 인코딩)
3.1.2.1. Content Codings
Content Coding은 주로 representations을 압축하거나 다른 용도로 사용할 수 있도록 하기 위해 사용되며 기본적인 미디어 타입의 정체성을 상실하지 않고 정보의 손실 없이 사용된다. representations은 코드화된 형태로 저장되고, 직접 전송되며, 최종 수신자에 의해서만 해독 된다. 모든 컨텐츠 코딩 값은 대소문자를 구분하지 않으며 HTTP Content Coding Registry에 등록해야한다. Accept-Encoding 및 Content-Encoding 헤더 필드에 사용된다. 정의되는 콘텐츠 코딩 값은 Compress Coding, Deflate Coding, Gzip Coding가 있다.
3.1.2.2. Content-Encoding
Content Encoding 헤더 필드는 미디어 타입의 정체성을 잃지 않고 압축될 수 있도록 하기 위해 사용한다. 하나 이상의 인코딩이 representations에 적용된 경우, 인코딩을 적용한 발신자는 해당 인코딩이 적용된 순서대로 Content-Encoding 헤더 필드를 생성해야한다. Content-Encoding 헤더는 Content-Type 헤더에 의해 참조되는 미디어 타입을 얻도록 디코드하는 방법을 클라이언트에게 알려준다. 서버에서는 요청 메시지의 표현에 허용되지 않는 콘텐츠 코딩이 있는 경우 415(Unsupported Media Type)상태 코드를 반환 한다.
3.1.3. Audience Language
3.1.3.1. Language Tags
Language Tags는 다른 사람에게 정보 전달을 위해 사용된 자연 언어를 식별한다. 컴퓨터 언어는 제외된다.
HTTP는 Accept-Language 및 Content-Language 헤더 필드 내에서 언어 태그를 사용한다. Accept-Language는 Language-range 문법을 사용하고, Content-Language에서는 Language-tag 문법을 사용한다.
Language Tag는 대소문자를 구분하지 않으며, 다중 Language Tag는 쉼표로 구분한다. 그리고 각 Language-tag는 -문자로 구분되는 한개 이상의 서브태그의 연속이다. Language-tag 내에서 공백은 허용되지 않는다.
Content-Language: ko // 단일 Language Tag
Content-Language: en-US // -로 구분되는 서브태그의 연속
Content-Language: en-US, ko // 다중 Language Tag
3.1.3.2. Content-Language
Content-Language 헤더 필드는 Represtation이 어떤 언어로 나타내는지 설명한다. Content-Language가 지정되지 않은 경우에는 Represtation이 모든 언어의 대상이라는것을 나타내기도 하지만 어떤 언어를 의도하는지를 모른다는 의미도 가질 수 있다. 그리고 모든 내용이 Language-tag의 대상 언어로만 작성되어 있지 않다는것을 알아야 한다. 그렇기 때문에 Represtation내에 다국어가 존재한다고 해서 다국어 사용자들을 위한것이 아니다. 우리는 아래의 예제 Represtation을 한국인 대상으로 제공하는것으로 가정하자.
안녕하세요 (Hello)
위와 같은 Represtation이 있을때 한국어와 영어가 함께 있다고 해서 Content-Language : en, ko라고 작성하는 것이 아니다.
우리는 한국인을 대상으로 제공하는 Represtation이므로 Content-Language : ko라고 작성하는것이 옳은 방법이다.
Content-Language는 모든 Media Type에 적용될 수 있다.
3.1.4. Identification
3.1.4.1 Identifying a Representation
완전한 또는 부분적인 Represtation을 메시지 페이로드(요청이나 응답의 바디)로 전송할 때, 발신자는 그 표현에 해당하는 리소스의 식별자를 제공하거나 또는 수신자가 결정하는것이 바람직하다.
Request Message
요청에 Content-Location 헤더 필드가 있는 경우, Content-Location 헤더의 값에 의해 식별된 리소스라고 주장된다. 이러한 주장은 다른 방법으로 검증될 수 있는 경우가 아니면 신뢰할 수 없다. (당연히 요청하는 쪽에서 리소스가 식별되어있다고 주장하니깐 검증되지 않은 경우라면 신뢰할 수 없음) 이 정보는 수정된 내역 링크(리소스가 수정 되기 이전의 내용을 가진 link라고 생각하는데… 현재 내가 요청하는 URI가 이전에는 이러한 Link를 가졌었다고 보내면서 해당 리소스가 식별이 됐었다라는것을 표현하고 싶은건가??)를 나타낼때는 유용할 수 있다.
이외에는 Content-Location 헤더가 없다면 페이로드는 식별되지 않는다.
Response Message
-
요청 메소드가 GET 또는 HEAD이고 응답 상태가 200(OK), 204(No Content), 206(Partial Content), 304(Not Modified)인 경우는 요청 URI는 식별된 유효한 리소스임을 나타낸다.
-
요청 메소드가 GET 또는 HEAD이고 응답 상태 코드가 203(Non-Authoriative Information)인 경우 서버와 클라이언트 사이에 있는 HTTP 프록시가 클라이언트에 도달하기 전에 응답을 변경하거나 추가 했다는것을 나타낸다.
-
Response에서 Content-Location 헤더 필드가 있고 헤더 값이 유효한 요청 URI와 동일한 URI인 경우 페이로드는 유효한 요청 URI에 의해 식별된 리소스이다.
-
Response에서 Content-Location 헤더 필드가 있고 헤더 값이 유효한 요청 URI와 다른 URI인 경우 발신자는 페이로드가 Content-Location 값으로 식별된 리소스의 표현이라고 단언한다. 이러한 주장은 다른 방법으로 검증될 수 있는 경우가 아니면 신뢰할 수 없다.
-
이외는 페이로드가 식별되지 않는다.
3.1.4.2. Content-Location
Content-Location 헤더 필드는 메시지의 페이로드에 해당하는 특정 리소스의 식별자로 사용할 수 있는 URI를 참조한다. 메시지가 생성될때 이 URI에 대해 GET 요청을 수행한다면 200(OK) 응답은 메세지의 페이로드에 포함된 representation을 담고 있다.
Content-Location = absolute-URI / partial-URI
Content-Location 값은 유효한 Request URI의 대체 값이 아니라 메타데이터를 표현한다.
Content-Location이 2xx(Successful) 응답 메시지에 포함되고 그 값이 유효한 요청 URI와 동일한 URI를 가리킨다면 수신자는 페이로드를 메시지 작성 날짜로 표시된 시점의 해당 리소스의 현재 representation으로 간주할 수 있다.
(그냥 요청했을때의 representation으로 생각하면 됨).
-
GET 또는 HEAD 요청의 경우, 이것은 서버가 Content-Location을 제공하지 않을 때의 기본 의미와 동일하다(제공하지 않다고 하더라도 URI를 GET 요청 후 2xx의 상태를 반환 한다는것은 리소스가 식별되었다는 뜻이니까?).
-
PUT 또는 POST와 같은 상태 변화 요청의 경우, 서버의 응답에 해당 리소스의 새로운 representation이 포함됨을 의미하며, 따라서 Content-Location을 제공하지 않고 해당 동작이 수행됐다 라는 representation (body와 상태코드로만 200, “It worked!”라고 응답한것)과는 구별이 된다.
이를 통해 어플리케이션은 후속 GET 요청 없이 로컬에 저장된 내용으로 업데이트할 수 있다. 예를 들어 내가 아래와 같은 form으로 송금하도록 한다.
<form action="/send-payment" method="post"> <p> <label>Who do you want to send the money to? <input type="text" name="recipient"> </label> </p> <p> <label>How much? <input type="number" name="amount"> </label> </p> <button type="submit">Send Money</button> </form>양식이 제출되면 사이트에서는 거래 영수증을 생성 후 서버는 향후 영수증 접근을 위해 Content-Location에 영수증 URL을 표시할 수 있다.
HTTP/1.1 200 OK Content-Type: text/html; charset=utf-8 Content-Location: /my-receipts/38 <!doctype html> (Lots of HTML…) <p>You sent $38.00 to ExampleUser.</p> (Lots more HTML…) -
외외 메서드에서 Content-Location은 페이로드가 요청된 행동의 상태에 대한 표현을 보고하는 것을 나타내며, 주어진 URI에서 동일한 보고를 사용할 수 있음을 나타낸다 (GET을 사용한 향후 접근)
요청 메시지로 Content-Location을 전송하는 사용자는 헤더에 보낼 값인 URI는 사용자가 이전에 Representation의 내용을 획득한 곳을 의미한다. 즉 사용자는 원래 Representation의 리소스에 대한 이전 링크를 제공하는 것이다.
요청 메시지에서 Content-Location 필드를 수신하는 서버는 정보를 Representation의 일부로 저장하기 위한 메타 데이터가 아닌 임시 요청 컨텍스트로 취급해야한다. 서버는 요청 처리를 안내하거나 소스 링크 또는 버전 메타데이터 내의 다른 용도로 저장하기 위해 이 컨텍스트를 사용할 수 있다. 단 서버는 요청 의미를 변경하기 위해 이러한 컨텍스트 정보를 사용해서는 안된다. 예를 들어 클라이언트가 협상된 리소스에 대해 PUT (리디렉션 x) 요청을 하고 서버가 PUT 요청을 수락하는 경우, 해당 리소스의 새로운 상태는 해당 PUT에 제공된 하나의 Representation과 일치할 것으로 예상된다. Content-Location은 협상된 표현 중 하나만 업데이트할 수 있는 역방향 컨텐츠 선택 식별자의 형태로 사용될 수 없다. 사용자가 후자의 의미를 원했다면 PUT을 Content-Location URI에 직접 적용했을것이다.
솔직히 Content-Location 헤더의 역할과 의미가 잘 이해가 되지 않는다. 사용되는 예제도 잘 보이지 않을 뿐더러… 일단은 넘기는 걸로 (2021-02-06) 다시 생각해보니 PUT /URL 요청시 Content-Location은 변경되는 리소스를 가르키는 /URL이 되어야한다는 의미인거같다. 만약 PUT /URL 요청시 Content-Location을 /URLe 라는 하나의 표현에 대한 업데이트를 한다는것은 말이 안되기 때문이다. Representation이라는 것은 리소스를 여러 모습으로 표현한것이지 변경되는것은 해당하는 표현이 아니라 리소스이기 때문이다. (라고 이해 했지만 아직 잘 …)
3.2. Representation Data
HTTP 메시지와 관련된 표현 데이터는 메시지의 페이로드 본문으로 제공되거나 메시지 의미 및 유효한 요청 URI에 의해 참조 된다. representation data는 representation metadata 헤더 필드에서 정의한 형식과 인코딩이다.
representation data의 데이터 타입은 헤더필드 Content-Type 및 Content-Encoding을 통해 결정 된다. 순서가 지정된 2계층 인코딩 모델을 정의한다.
representation-data := Content-Encoding( Content-Type( bits ) ) 컨텐츠 타입으로 지정된 데이터를 인코딩한것이 Representation Data가 되는것이다.
3.3. Payload Semantics
일부 HTTP 메시지는 payload 메시지로 전체 또는 부분 representation을 전송한다. 경우에 따라 페이로드에 관련 표현의 헤더필드(HEAD 메서드의 응답) 또는 representation data의 일부(206 (partial Content) 상태코드)만 포함될 수 있다.
요청에서 페이로드의 목적은 메서드 의미론에 의해 정의된다. 예를 들어 PUT 요청의 페이로드에 있는 representation은 요청이 성공적으로 적용될 경우 대상 리소스의 원하는 상태를 나타낸다. (예를 들어 서버에 저장된 1번 user의 name이 user1이고 우리는 그 유저의 이름을 user2로 변경하고 싶다. 이때 put 요청을 아래처럼 나타 낼 수 있다.
PUT http://localhost/users/1
body : { 'name' : 'user2' }
성공적으로 응답 결과가 왔을 경우에는 1번 유저의 이름이 user2로 바뀌게 됨으로 요청에서 페이로드에 있는 representation은 리소스의 원하는 상태를 나타낸것임을 알수 있다.)
POST 요청의 페이로드에 있는 representation은 대상 리소스가 처리할 정보를 나타낸다. (예를 들어 서버에 새로운 user를 만드는 요청을 보내 보자.
POST http://localhost/users
body : { 'name' : 'newUser' }
성공적으로 응답 결과가 왔을 경우 유저가 생성이 되었다는 의미이므로 요청에서 페이로드에 있는 representation은 리소스가 처리할 정보를 나타낸것임을 알 수 있다.)
이에 대해 페이로드의 목적은 요청 메소드와 응답 상태 코드에 의해 모두 정의된다. GET에 대한 200(OK) 응답의 페이로드는 메시지 시작일에 리소스의 현재 상태는 나타낸다. POST에 대한 응답에서 200(OK) 응답의 페이로드는 처리 결과 또는 처리 적용 후 대상 리소스의 새 상태를 나타낼 수 있다. 오류 상태로 반환되는 경우 응답 메시지에 오류 상태와 오류 해결을 위한 제안되는 다음 단계를 설명하는 것과 같은 오류 조건을 나타내는 페이로드가 포함되어 있다.
연관된 representation보다 페이로드를 구체적으로 기술하는 헤더 필드를 payload header fields라고 한다. 페이로드 헤더 필드는 메시지 구문 분석에 대한 영향 때문에 이 명세의 다른 부분에 정의되어 있다.
- Header Field Name
- Content-Length
- Content-Range
- Trailer
- Transfer-Encoding
3.4. Content Negotiation
응답이 성공이던 오류이던 페이로드 정보를 전달할 때, 서버는 다른 형식, 언어, 인코딩과 같은 정보를 표시하는 방법이 있다. 여러 사용자마다 어떤 representation을 가장 잘 전달하는지에 영향을 미칠 수 있는 능력, 특성, 선호도가 다를 수 있다. 이러한 이유로 HTTP는 콘텐츠 협상의 메커니즘을 제공한다.
이 명세는 프로토콜 내에서 가시화할 수 있는 콘텐츠 협상의 2가지 패턴을 정의한다. 서버가 사용자의 명시적 선호도에 따라 표현을 선택하는 proactive (사전)협상과, 서버가 사용자 에이전트가 선택할 수 있는 표현 목록을 제공하는 reactive(대응)협상이 있다. 그외 콘텐츠 협상 패턴으로는 사용자 매개변수에 따라 선택적으로 렌더링 되는 여러 부분으로 구성된 contitional contet, 사용자 특성에 따라 추가(더 구체적인) 요청을 하는 스크립트가 포함된 active content, Transparent Content Negotiation등이 있다. 여기서 콘텐츠 선택은 중개자가 수행한다. 이러한 패턴은 상호 배타적이지 않으며, 적용성과 실용성에서 각각 절충점을 가진다.
모든 경우에서 HTTP는 리소스 의미론을 인식하지 못한다. 시간이 지남에 따라, 그리고 시간에 따라, 그리고 콘텐츠 협상의 다양한 차원에 걸쳐, 그리고 시간에 따른 리소스의 관찰된 표현의 sameness에 대해 서버가 요청하는 응답하는 일관성은 전적으로 어떤 항목이나 알고리즘이 그러한 응답을 선택하거나 생성하는가에 의해 결정된다 HTTP는 커튼 위에 있는 사람에게 관심을 두지 않는다.
그냥 우리가 요청하는 헤더와 메서드와 리소스의 의미를 HTTP는 모른다는 말로, 개발자는 요청하는 의미대로 동작하게 만들어야한다는 뜻
두 콘텐츠 협상과 관련된 내용은 MDN에서 설명된 내용을 가져왔다. 가장 깔끔하게 쓰여졌다고 생각한다.
3.4.1. Proactive Negotiation (MDN 내용 참고)
서버 주도 컨텐츠 협상 혹은 주도적인 협상에 있어서, 브라우저(혹은 사용자 에이전트라면 어떤 다른 종류든지)는 URL을 이용해 몇 개의 HTTP 헤더를 전송합니다. 이런 헤더들은 사용자의 우선적인 선택을 나타냅니다. 서버는 그것들을 힌트로써 사용하며 내부 알고리즘은 클라이언트로 서브하기 위한 최선의 컨텐츠를 선택하게 됩니다. 이 알고리즘은 서버 특유의 것이며 표준으로 정의된 것은 아닙니다.
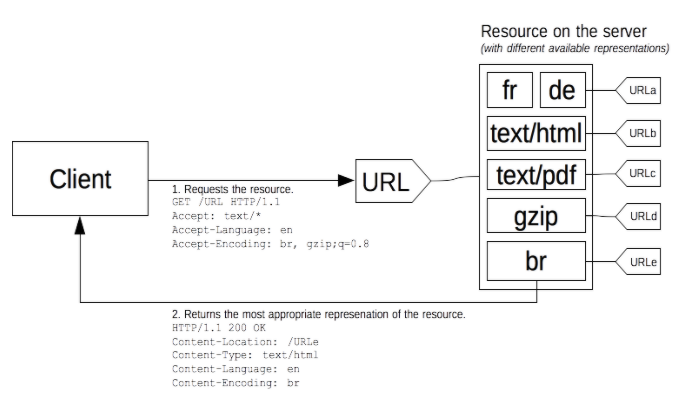
HTTP/1.1 표준은 서버 주도 협상을 시작하는 표준 헤더 목록(Accept, Accept-Charset, Accept-Encoding, Accept-Language)을 정의하고 있습니다. 엄밀히 말하자면 User-Agent이 리스트 내에 없긴 하지만, 해당 헤더는, 좋은 관례가 아니라고 판단될지라도, 때때로 요청된 리소스의 특정 프레젠테이션을 전송하는데 사용되기도 합니다. 서버는 실제로 컨텐츠 협상에 있어 어떤 헤더가 사용될 지 (더 엄밀히 말하자면 연관된 응답 헤더) 가리키기 위해 Vary 헤더를 사용하므로 캐시는 최적으로 동작하게 됩니다.
이것과 더불어, 클라이언트 힌트라고 부르는 헤더들을 이용 가능한 헤더 목록에 추가하려는 실험적인 제안도 존재합니다. 클라이언트 힌트는 사용자 에이전트가 실행 중인 기기의 종류가 무엇인지를 알려줍니다(예를 들어, 데스크톱 컴퓨터인지 모바일 기기인지)
서버 주도 컨텐츠 협상이 리소스의 특정 프레젠테이션에 동의하기 위한 가장 일반적인 방법이긴 하지만, 몇 가지 결점을 가지고 있습니다:
서버는 브라우저에 대한 전체적인 지식을 가지고 있지 않습니다. 클라이언트 힌트 확장이 있더라도, 서버는 브라우저의 수용 능력에 대한 완벽한 정보를 가지고 있진 않습니다. 클라이언트가 선택하는 리액티브 컨텐츠 협상과는 다르게, 서버 선택은 항상 다소 임의적입니다. 클라이언트에 의한 정보는 상당히 장황하며(HTTP/2 헤더 압축은 이런 문제를 완화시킵니다) 사생활 침해에 대한 위협을 가지고 있습니다(HTTP 핑거프린팅). 주어진 리소스의 몇몇 프레젠테이션이 전송되므로, 샤드된 캐시들은 덜 효율적이며 서버 구현은 좀 더 복잡해집니다.
3.4.2. Reactive Negotiation (MDN 내용 참고)
서버 주도 협상은 몇 가지 불리한 점 때문에 고통을 줍니다: 그것은 확장하기가 용이하지 않습니다. 협상 내에서 사용하는 기능 당 한 가지 헤더가 존재해야 합니다. 만약 스크린 크기, 해상도 혹은 또 다른 치수를 사용하고자 한다면, 새로운 HTTP 헤더가 반드시 만들어져야 합니다. 헤더의 전송은 반드시 모든 요청 상에서 이루어져야 합니다. 이것은 몇몇 헤더들에 있어서는 그리 문제될 것은 아니지만, 그런 헤더들이 결국 증가하여, 메시지 사이즈가 성능에 악영향이 끼치는 상황이 올 수도 있습니다. 정확한 헤더가 전송되면 전송될수록, 불확실성도 더욱 더 전송되어, 좀 더 많은 HTTP 흔적과 그와 관련된 개인정보들이 남게 됩니다.
HTTP의 초창기부터, 프로토콜은 또 다른 협상 유형을 허용했습니다: 에이전트 주도 협상 혹은 리액티브 협상. 이 협상에서, 애매모호한 요청과 맞닥뜨렸을 경우, 서버는 사용 가능한 대체 리소스들에 대한 링크를 포함하고 있는 페이지를 회신하게 됩니다. 사용자는 해당 리소스들을 표시하고 사용하려는 리소스를 선택하게 됩니다.
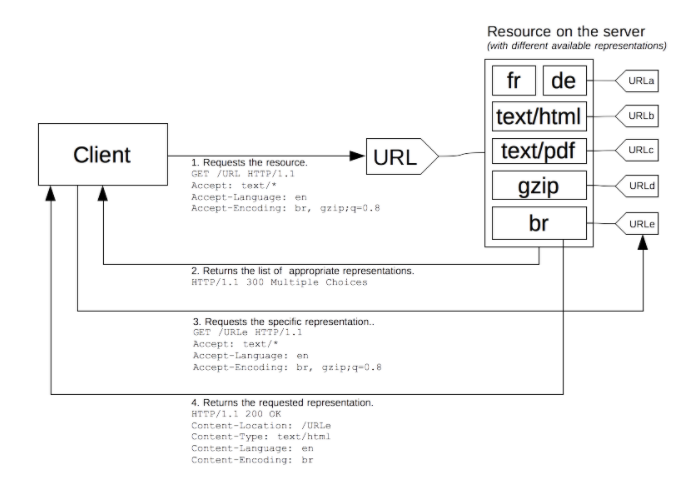
불행하게도, HTTP 표준은 그 과정을 쉽게 자동화하는 것을 지원하지 않고, 사용 가능한 리소스 중에서 선택하도록 허용하는 페이지의 형식을 명시하지 않고 있습니다. 게다가 서버 주도 협상으로의 회귀로, 이 방법은 스크립팅, 특히 자바스크립트 리다이렉션과 함께 거의 항상 사용됩니다: 협상 기준을 점검하고 난 뒤에, 스크립트는 리다이렉션을 실행합니다. 두번째 문제는 실제 리소스를 가져오는데 한 개 이상의 요청이 필요로 해서, 사용자에 대한 리소스 효용성이 떨어진다는 것입니다.